

投票软件用哪个好 【人工神经网络PAI实战演练】—— 轻松玩人工智能技术之具体描述

实体模型练习与线上预测分析服务项目、推荐系统四部曲、人工神经网络PAI实战演练、更多精彩,尽在阿里云服务器新年Hi购季,开发人员主会场 - 阿里云服务器
【人工神经网络PAI实战演练】—— 轻松玩人工智能技术之产品价格预测分析-云栖社区-阿里云服务器
【人工神经网络PAI实战演练】—— 轻松玩人工智能技术之你最爱哪一个男孩子?-云栖社区-阿里云服务器
【人工神经网络PAI实战演练】—— 轻松玩人工智能技术之美食小吃-云栖社区-阿里云服务器
【人工神经网络PAI实战演练】—— 轻松玩人工智能技术之运用GAN自动生成二次元头像-云栖社区-阿里云服务器
论文前言
人工智能技术并不是新的专业术语,这一定义古已有之,大概从80时代初逐渐,电子计算机专家逐渐设计方案可以学习培训和效仿人们个人行为的优化算法。人工智能技术的发展趋势坎坷往前,随着着信息量的增涨、计算力的提高,人工神经网络的火爆,及其深度神经网络的暴发,人工智能技术获得迅速发展趋势,快速席卷全球。
人工智能技术的研究领域也在不断发展,早已包含数据管理系统、人工神经网络、演变测算、模糊逻辑、机器视觉、自然语言处理、推荐算法等众多行业。可以毫无夸大地说,人工智能应用已经像100很多年前的电量一样,将要更改所有领域。每一个公司也不期待在此次的浪潮中脱队,怎么样才能运用AI战胜自己的公司开展转型发展呢?AI行业zhu名专家学者吴恩达在不久前对于该问题,发布了《AI转型指南》。
人工神经网络,做为完成人工智能技术的一种方式,针对人工智能技术的进步起着十分关键的功效。而深度神经网络,做为人工神经网络中的一种技术性,也是势如破竹地完成了各种各样每日任务,巨大促进了各行各业向着人工智能技术的方位迈进。下边这幅图,十分品牌形象地概述了三者关系。
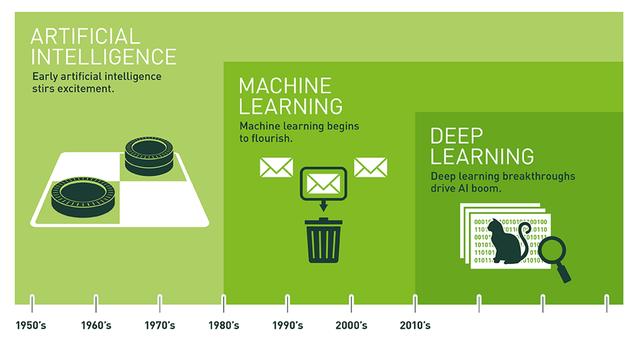
总而言之,人工智能技术、人工神经网络、深度神经网络早已深入细致到公司生产加工和自己日常生活的各个方面。可以娴熟应用人工神经网络处理日常生活生产制造之中的运用,把握人工智能应用,针对公司和本人的长久发展趋势越来越尤为重要。
1. 人工智能算法
人工神经网络(Machine Learning, ML)是一门多行业交叉科学,涉及到概率统计、应用统计学、逼近论、凸剖析、时间复杂度基础理论等两门课程。人工智能算法依据处理的工作种类,可以分成随机森林算法、回归算法、聚类算法等,深度神经网络做为人工神经网络中非常独特的一类优化算法,是神经网络模型的拓展和拓展。
人工神经网络大概可以分成监督学习和非监督学习。监管式学习培训,由已经有的数据信息包含I/O,练习实体模型涵数;随后把新的导入数据信息带进实体模型涵数,预测分析数据信息导出。涵数的导出如果是一个持续的值,则称之为多元回归分析,假如导出是离散变量标值,则称之为归类。与监督学习相对性应的是无监督学习,这时数据信息沒有标明信息内容,聚类分析是非常典型的无监督学习。
阿里云服务器设备在线学习平台PAI(Platform of Artificial Intelligence),为传统式人工神经网络给予上千种优化算法和规模性分布式计算的服务项目;为深度神经网络顾客给予单机版多卡、多机多卡的性价比高資源服务项目,适用全新的机器学习开源框架;协助开发人员和客户需求弹力扩缩存储资源投票软件用哪个好,轻轻松松完成线上预测分析服务项目。
PAI-Studio封装形式常见人工智能算法及丰富多彩的交互部件,客户不用编码基本,根据拖拖拉拉拽就可以练习实体模型。
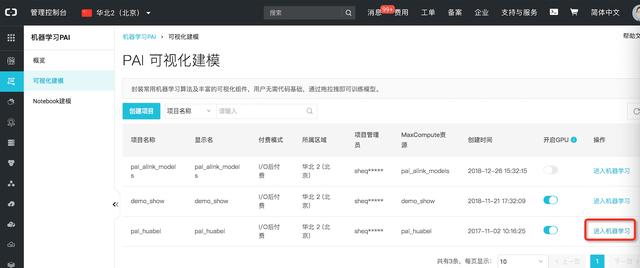
如下所示图例,在阿里云服务器设备在线学习平台启用账户以后,进到管理方法控制面板—交互模型,依据自身的必须新建项目,进到人工神经网络就可以进到到PAI-Studio开展应用。

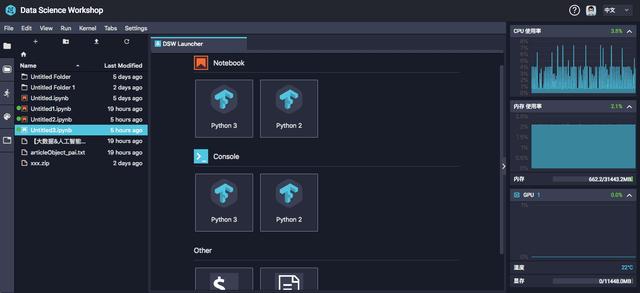
PAI-Studio上根据拖动优化算法部件,搭建试验,开展实体模型练习投票软件用哪个好,练习好的实体模型可以一键布署到PAI-EAS。设备学习模型线上布署作用可以将您的实体模型一键布署为Restful API,您可以根据HTTP要求的形式开展读取(使用说明书文本文档)。
PAI-DSW(Data science workshop)是特意为优化算法开发人员提前准备的云空间深度神经网络开发工具,客户可以登陆DSW开展编码的开发设计并运作工作中。现阶段DSW内嵌了PAI精英团队深层提升过的Tensorflow架构,与此同时还可以根据开启console对话窗口自主安裝必须的第三方库。
1.1 随机森林算法
随机森林算法运用普遍,例如新闻内容归类、产品品类预测分析、文字文本分析、电子邮件废弃物过虑、图像分类、异常检测等。普遍的随机森林算法有k近邻、朴素贝叶斯、决策树、SVM、运用adaboost提高弱支持向量机等。
k近邻算法(kNN),简易地说,是选用精确测量不一样特征根中间间距的方式 开展归类。kNN的基本工作原理是:存有一个样版结合,也称之为训练样本集,而且样版集中化每一个数据库都存有标识,即我们知道样版集中化每一数据信息与隶属归类的对应关系。键入沒有标识的新数据后,将新数据的每一个特点与样版集中化数据信息相对应的特性开展较为,随后优化算法获取样版集中化特点最类似数据信息(近期邻)的归类标识。一般来说,大家只挑选样版数据信息集中化前k个最类似的数据信息投票软件用哪个好,这就是k-近邻优化算法中k的来源。最终,挑选k个最类似数据信息中发生的次数较多的归类,做为新数据的归类。
决策树,比较适合了解,下列图为例子,依据某一人的特点(年纪、是不是学员、个人信用状况)来实现归类,分辨是不是可以放借款为他。转化成的决策树如下所示图例。决策树观念,事实上便是找寻最纯粹的划定方式,关键根据决策树的结构和修枝。
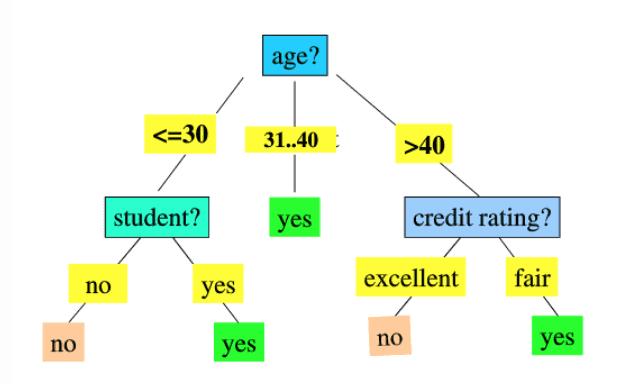
虽然有修枝这些方式,一棵树的转化成毫无疑问或是比不上多株树,因而就拥有随机森林,处理决策树泛化能力弱的缺陷。依据练习数据信息,结构m个CART决策树,这m个CART产生随机森林,根据投票决议結果,决策数据信息归属于哪一类(投票体制有一票否决制、极少数听从大部分、权重计算大部分),这就是随机森林的方式。
朴素贝叶斯,在其中的质朴一词的由来便是假定各特点中间互不相关。这一假定促使朴素贝叶斯优化算法越来越简易,但有时候会放弃一定的归类准确度。贝叶斯公式界定如下所示:
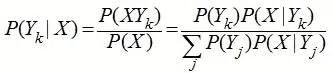
公式计算的右侧是汇总历史时间,公式计算的左侧是预见未来,假如把Y看得出类型,X看得出特点,P(Yk|X)便是在已经知道特点X的状况下求Yk类型的几率,而对P(Yk|X)的测算又所有转换到类型Yk的特点遍布上去。朴素贝叶斯优化算法逻辑性简易,非常容易完成,测算流程中的空间和时间花销也相对比较小。朴素贝叶斯假定特性中间互不相关,这类假定在具体工作中通常不是创立的。在特性中间关联性越大,归类偏差也就越大。
svm算法(Support Vector Machine, SVM)的基本上实体模型是在特点室内空间上寻找最好的分离出来超平面促使训练集上正负极样版间距较大。SVM是用于处理二分类问题的有监督学习优化算法,在引进了核方式以后SVM还可以用于处理非线性问题。一般SVM有下边三种:(1)硬间距svm算法(线形可分svm算法):当练习数据信息线形可分时图,可根据硬间距较大有机化学得一个线形可分svm算法。(2)软间距svm算法:当练习数据信息类似线形可分时图,可根据软间距较大有机化学得一个线形svm算法。(3)非线性svm算法:当练习数据信息线形不能分时图,可根据核方式及其软间距较大有机化学得一个非线性svm算法。
AdaBoost,每一种随机森林算法都是有自身的优点和缺点,大家把归类实际效果并不是有效的支持向量机称为弱支持向量机,归类效果非常的好的支持向量机称为强支持向量机。Adaboost优化算法基本概念便是将好几个弱支持向量机(弱支持向量机一般采用单面决策树)开展科学合理的融合,使其变成一个强支持向量机。Adaboost选用迭代的观念,每一次迭代只练习一个弱支持向量机,练习好的弱支持向量机将参加下一次迭代的应用。换句话说,在第N次迭代中,一共就会有N个弱支持向量机,在其中N-1个是之前练习好的,其各种各样主要参数都不会再更改,此次练习第N个支持向量机。在其中弱支持向量机的相互关系是第N个弱支持向量机更很有可能分对前N-1个弱支持向量机没分对的数据信息,最后归类导出需看这N个支持向量机的综合性实际效果。#p#分页标题#e#
上边先后对常见的随机森林算法开展了详细介绍,PAI-Studio中也给予了相对的优化算法部件,假如需要应用,可以立即拖动相匹配部件,配备有关主要参数就可以。

1.2 回归问题
重归与归类的不一样,就源于其总体目标自变量是持续标值型。多元回归分析依据已经知道数据信息练习出实体模型(即线性回归方程),对新的数据预测时,只必须带入到实体模型,测算出预测分析标值。重归几乎可以运用到一切事儿,例如预测分析产品价格、股票价格发展趋势预测分析、预测分析明日温度、预测分析某类状况产生几率(可依据几率尺寸转换为归类问题)、预测分析广告宣传点击量开展筛选等。较为常见的再现方式具体有回归分析和逻辑回归。
回归分析非常简单,叙述了变量和自变量中间的简易线性相关,大家的总体目标是根据特点的搭配来学习培训到要预测分析涵数式(线形式),大家用X1,X2..Xn 去叙述feature里边的份量,我们可以作出一个可能涵数: